
.png%3Falt%3Dmedia%26token%3D12c0d17f-7432-4b71-9024-0a4489ed4d45&w=3840&q=75)
Supervised Learning for Beginners: From Data to Predictions
Key Highlights
Supervised learning trains machine learning models using labeled data with known answers. This approach enables learning models to learn from training data, resulting in accurate predictions on new data points. The two main types are classification and regression, each solving different business problems. The pros of using supervised learning in data analysis include achieving high accuracy in predictions when quality labeled data is available, and the ability to generalize well to new data. However, its cons include the dependency on large quantities of accurately labeled data, which can be costly and time-consuming to obtain, and a potential decrease in effectiveness when applied to types of data the model has not seen during training.
It learns from training data to make accurate predictions on new data points.
The two main types are classification and regression, each solving different business problems.
Classification predicts categories like spam or fraud, while regression predicts a continuous value.
Popular methods include logistic regression, linear regression, decision trees, random forest, SVM, and Naive Bayes.
Beginners can use supervised learning in real use cases across healthcare, finance, education, and recommendation systems.
Introduction
Machine learning is an important part of artificial intelligence. Supervised learning is one of the best ways to get started. If you are new to AI, this subject can help you see how learning models use data to make good choices and guesses. You see supervised learning in action in things like spam filters and tools that tell you house prices. It shows up in many systems we use every day. In this guide, you will get to know what supervised learning is, how it works, and why it is important for beginners, people who make software, and people who work with analytics.
What Is Supervised Learning?
 Supervised learning is a type of machine learning. In this, a supervised learning algorithm gets trained using labeled data. Each example in the training data has an input and the right answer. This helps the system learn how inputs and outputs are linked.
Supervised learning is a type of machine learning. In this, a supervised learning algorithm gets trained using labeled data. Each example in the training data has an input and the right answer. This helps the system learn how inputs and outputs are linked.
The learning algorithm looks at what it guesses and checks it with what the answer should be. Then, it gets better as it learns from the training data. People use supervised learning when they know what the target result is and want the system to give accurate predictions on new data.
Defining Supervised Learning in Simple Terms
Think of supervised learning like learning with an answer sheet. You show the computer some examples, and each example comes with the right answer. The learning algorithm looks at these pairs and finds patterns that match the input to the output.
Supervised learning is helpful for machine learning tasks. It lets the computer learn from old cases. For example, you can give it labeled data on emails marked as spam or not. The computer then starts to spot what makes one email look risky and one look safe. This way of learning also works well for image recognition, risk assessment, and medical diagnosis.
After training, the model can use what it learned to handle new data. That’s the main idea of what supervised learning does in machine learning. It learns from examples with answers, then makes guesses about new data later.
Why It Is Called “Supervised”: The Role of Labels
The word “supervised” is important because it means the model is guided during training. The model is not just guessing. It learns with help. Labeled data is used, so the right answer is already linked with each input.
These labels are like a teacher for the model. In training data, the input values are given along with target answers like “spam,” “not spam,” or maybe a house price. Since we know the answers, the system can see where it made mistakes and change the model to make it better over time.
That is why labeled data is so key for supervised learning methods. If there are no labels, the model does not know what answer to aim for. Labels give the learning process order. They make it possible to check how well the system is doing, and help the system find a better way from input to final answer.
How Supervised Learning Works Step-by-Step
 Building supervised learning models often has a clear path to follow. You first collect data, then add labels to it. After that, you train the system using this data. You test it and try to make it better. This step-by-step training process helps learning models find patterns before they deal with new data points.
Building supervised learning models often has a clear path to follow. You first collect data, then add labels to it. After that, you train the system using this data. You test it and try to make it better. This step-by-step training process helps learning models find patterns before they deal with new data points.
Let’s look at an example with house price prediction. The model checks the training data and looks at features like the size, age, and how many rooms the house has, along with what homes sold for in the past. With this, the learning models guess what new homes might cost, even if they have not seen those homes before. The next parts talk more about this process.
Collecting and Labeling Data for Machine Learning
Everything starts with data collection. You get input data that fits the problem you want to work on. For something like a house price tool, you need things such as location, age, size, and how many rooms there are. The model will study these data points.
After that, you need labeling. This means each example should have the right answer with it. If you are working with house prices, the label is the sale price. If you are trying to sort spam, the label is either spam or not spam. Labeled data that is good helps a lot because you can later check your outcomes against the real answers.
Common steps are:
Collect input data that is relevant from historical data.
Remove things like clear mistakes, repeats, or missing info.
Attach the right label to every example.
Make sure the data points match what you see in the real world.
Training, Testing, and Improving Your Model
When the data is set, the supervised learning model gets trained on a training set. At this point, it looks for how the inputs and outputs work together. The main goal is to cut down on errors and find patterns that can help on new data.
Once it trains, you check how well it works by testing it with other data sets. This is important because if the model does well only on the training data, it does not help much in real life. Good models should deal with things they have not seen before, not just copy the training set. This is how you start to see if the model can do well in handling new things.
To get better results, teams often:
Compare how the model predicts with the training data sets and the testing datasets.
Make changes to the model when the mistakes keep up.
Train the model again with better or more even data if they have to.
Understanding Labeled Data in Supervised ML
A labeled dataset is very important for supervised ML. It includes input data and the right answer for each row. These known outcomes tell the model what it should guess, and help see how well it is doing when it learns.
You also need to do feature selection. This means you choose helpful inputs. You separate them from the target variable. When your data is clear and fits the problem, the model learns fast. It will give better results. Now, let's make features and targets simple with examples that you can follow.
Features vs Target Variables Explained with Examples
Features are the details that the model uses to learn. These input features can be things like the size of a house, the age of it, where it is, or how often a student logs in to a course system. Every row in a dataset shows data points that explain one example.
Target variables are the answers the model tries to predict. When you want to guess the price of a house, the target is how much the house will sell for. In a problem about passing or failing, the target is if the student passed. The learning process links input features to the target.
Here’s an easy way to see how it works. If the goal is to predict if someone will leave (churn), usage time and how many devices they have are input features, while “churn” or “retain” is the target. When people ask what supervised learning does, the fast answer is this: it uses features to learn and it guesses target variables.
Difference Between Training and Testing Datasets
Many beginners confuse training data and testing data, but they play different roles. The training set teaches the model. The testing data checks whether the model can perform well on unseen examples. Both parts are necessary in supervised learning.
If you only use one of these data sets, you may get a false sense of success. A model can look strong on familiar examples and still fail badly on new inputs. That is why teams split data before model building.
Dataset Type | Main Purpose | Example Use |
|---|---|---|
Training set | Teaches the model patterns from labeled examples | Learn how home features connect to price |
Testing data | Measures performance on unseen records | Check predicted prices against real prices |
Result | Helps judge model quality | Detect overfitting or weak generalization |
Key Types of Supervised Learning Explained
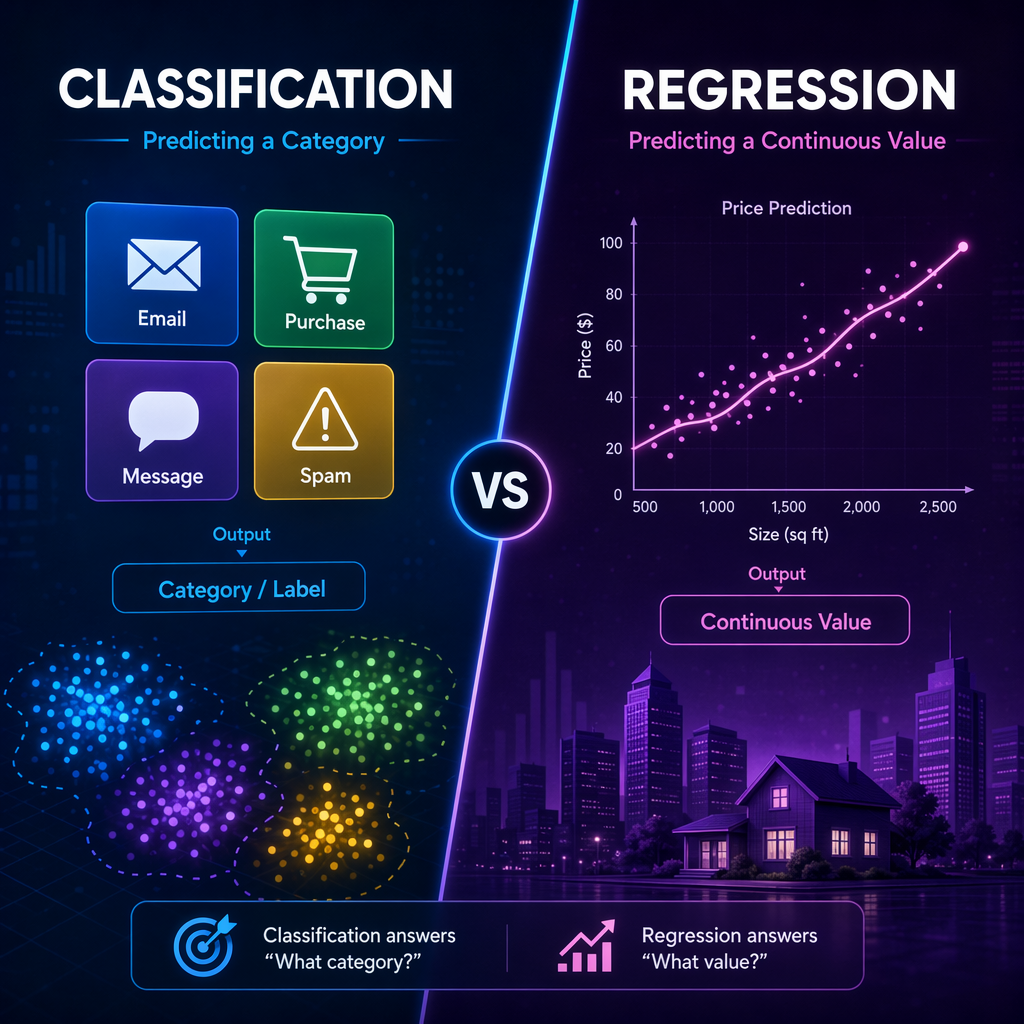 Most supervised learning problems can be put into two main types. These are classification and regression. Both of these use labeled samples, but the output you get is not the same. This difference shapes the algorithms you use, how you test the models, and many common use cases in business.
Most supervised learning problems can be put into two main types. These are classification and regression. Both of these use labeled samples, but the output you get is not the same. This difference shapes the algorithms you use, how you test the models, and many common use cases in business.
Classification is used when you want to put things into groups or classes. For example, if you want to check if an email is spam, this is classification. Regression is for when you need a number, like if you want to find out the price of a house. That is a regression problem. The next parts will show these main types with simple examples and explain their use cases in a way that is easy to get.
Classification: Grouping Data into Categories
Classification is used when the answer must be one choice in a set of classes. The model looks at the samples that have labels. It learns the patterns that go with each group. When given something new, a classification model picks the class that fits best.
One type is binary classification. There are only two possible answers in binary classification. For example, a message can be spam or not spam. It could also be disease or healthy. The system checks the data and puts it into one side or the other.
There can be more than two groups with classification too. For example, a photo could be marked as a cat, a dog, or a rabbit. In each case, supervised learning is used for these classification problems. The system studies known labels to learn. Later on, it puts new information into the right group based on what it learned.
Regression: Predicting Continuous Values
Regression is something you use when you want to guess a continuous value, not a category. For example, it could help you find out a house price, total sales, stock price, or even temperature. The output is a number. It can go up or down within a certain range.
One good and common way is called linear regression. In this method, the model checks for a link between inputs and output. Then it tries to guess future values based on the pattern it finds. Many regression algorithms follow this idea. Some work better when the trend is simple, while others are better for patterns that are not as simple.
This is why regression helps you with forecasting. If you have enough historical data that shows how things are connected, the model can make a guess about what will happen next. That is why there is a lot of regression in pricing, planning for money, and trying to predict demand.
Inside Classification—Techniques and Examples
Classification is a key part of supervised learning. You see it often in systems that help us every day. A classification model learns from records that already have labels. Then it uses this knowledge to put new records into the right group.
There are many kinds of classification algorithms. Each uses its own learning techniques. The main goal is to get the classes right. Some work best for tasks where you just answer yes or no. Others can sort things into many categories. In the next sections, you will see what types of tasks there be. After that, you will learn about real-world use cases for these models.
Binary vs Multi-class Classification Tasks
Binary classification is when there are just two possible results. For example, a model can decide if an email is spam or not spam. It could also check if a patient is sick or healthy, or if a loan is risky or safe. Each job has two clear classes.
Multi-class classification is used when there are more than two different classes. For example, a model may call a picture a cat, dog, or bird. It still uses labeled data and looks at data points, but now it picks from more choices instead of just two.
The main idea is simple. Every classification step puts a piece of data into a group. The thing that changes is how many groups there are. There are only two groups in binary classification. There are many in multi-class classification.
Real-World Classification Use Cases in India
You can see how classification is used in many industries in India. Banks, healthcare, digital platforms, and education services all use models that put things into different groups. This helps their teams work quickly and in the same way every time.
Many of the tasks are easy to spot in daily life. For example, a digital platform can look for unsafe transactions. An app can tag what it sees in photos or videos. A hospital can use patterns in patient records to help doctors make the right call. These are good examples of how supervised learning is used every day.
Common use cases are:
Fraud detection in digital payments and banking work
Medical diagnosis help from organized clinical data
Image classification in visual tools and to check documents
Recommendation systems that group user activity into useful tips
Popular Algorithms Used in Classification
Many algorithms help build a good classification model. Each algorithm learns from data in its own way. The best one for your task depends on the problem, the data you have, and if you need the model to be explained well.
People often use logistic regression, decision trees, random forest, SVM, and Naive Bayes. Some methods work fast and are easy. Others can handle complex models. In the next two parts, I will tell you how these algorithms work, what makes them good, and where people usually use them.
Logistic Regression, Decision Trees, Random Forest, and SVMs
Logistic regression is a method that you can use for classification problems where the outcome is one of a few choices. This is most helpful with two options, like pass or fail, or spam or not spam. It works well when you want to get chances or probabilities for each outcome. It is a simple and straight-forward tool and is often used for data that is set up in rows and columns.
Decision trees go step by step, like an if-else path, to find the answer. They can work for both picking groups and for numbers too. A random forest uses many decision trees at the same time and combines their answers. This makes the final result better and gives more steady and reliable answers. It can deal with more different kinds of data.
SVM, which stands for support vector machine, is another strong way to do classification algorithms. It picks a line or a border that splits different groups in your data. It is very good when getting a clear split between choices is important. These methods can help answer questions like churn prediction, fraud detection, or labeling objects in pictures.
Naive Bayes: Advantages and Typical Applications
Naive Bayes is a way to sort data, like text, by using the ideas from probability. It gives you a quick method to group things. This works well for jobs where you want to sort a text into groups, like finding spam in your email.
The good thing about Naive Bayes is speed. It can handle a lot of data fast. The model does not need to be deep or hard to set up. This works great when feature selection is important. You can bring in many pieces of input, and it will not be tough to run.
People usually use it for email spam filtering, looking for messages that show positive or negative feelings, and putting documents into the right place. The quality of a classification model still depends on clear groups and good input features. Naive Bayes may not always be the newest method, but it is still useful and honest for many easy and common tasks.
Exploring Regression Algorithms and Their Uses
Regression algorithms are used when you want to guess a continuous value by learning from past data. These methods do not sort your data into groups or classes. Instead, they help you see how input features are linked to numbers, like price, demand, or revenue.
There are different types of regression methods and each one matches certain patterns. Some work best when the relationship is close to a straight line. Others are better for tricky data that doesn’t fit a line. To keep things clear, the next parts cover common ways to predict using regression. You will also see how tree-based regression can help solve business problems.
Linear & Polynomial Regression for Forecasting
Linear regression is one of the simplest regression algorithms. It predicts values by drawing a straight line between the inputs and the output. If your training data shows that sales go up when advertising increases, or that home price rises with size, linear regression can work well.
But sometimes the link between the input and output is not a straight line. Polynomial regression is good for those cases. It uses a curved line to show the changing patterns in the data. This is useful when forecasting is not a simple relationship.
Both linear regression and polynomial regression can be used for forecasting. You can use them to estimate house prices, predict sales, or study trends with historical data. The right method depends on if your data follows a straight path or takes a more complex turn.
Decision Tree and Random Forest Regression for Business Problems
Decision trees can do more than sort things into groups. They can also help you guess values by breaking things down using clear rules. This is good for business cases where things do not follow a straight line or are hard to spot.
Random forest regression takes this a step ahead. It puts together many trees. This makes one strong system and helps the results be right more often. It also keeps things steady even if the data changes a little. This is a top choice when the data is not all the same and one model alone may be too easy to tip.
You can use the methods in real jobs. Many teams use them for things like guessing demand, revenue, or what a customer is worth. For many jobs, decision trees and random forest ways give the right mix of good guesses and simple use.
Conclusion
In the end, supervised learning is a key idea in machine learning. It helps us make smart guesses by using labeled data. When you learn about both classification and regression, and how they work in real-life areas like healthcare checks and e-commerce picks, you start to see the true power of making choices with data. If you want to get into this field, you should know that getting good at these tools will grow your skills and give you a shot at new jobs in AI. Want to learn more about supervised learning? Sign up now, and start your path to getting better at this fun part of tech.