
.png%3Falt%3Dmedia%26token%3D867cd575-0434-424f-8ab0-f1f10e6182fc&w=3840&q=75)
How Machine Learning Works: Simple Explanation with Examples
Key Highlights
Machine learning works by learning from training data, not by following fixed rules you write for every case.
You’ll see the different types, including supervised learning and unsupervised machine learning, and what each is best for.
ML models do pattern recognition through data analysis and repeated model training.
Deep learning uses neural network layers to learn complex tasks from large datasets.
After training, a trained model can handle new data to predict output values.
This approach powers many artificial intelligence use cases you already use.
Introduction
Machine learning is a fast-growing part of computer science and artificial intelligence. With this, you don’t need to give the computer every detail or order. Instead, you use data to train a system so it can make choices on its own. This idea may look large, but it gets simple if you break it down. In this guide, you will see how machine learning works, what an ml model is, and why it is important in daily life and business.
What Is Machine Learning?
 Machine learning is a way to create a machine learning model that uses data to help with complex tasks. It helps with pattern recognition, prediction, and sorting things into groups. You do not need to give step-by-step rules for each case.
Machine learning is a way to create a machine learning model that uses data to help with complex tasks. It helps with pattern recognition, prediction, and sorting things into groups. You do not need to give step-by-step rules for each case.
In computer science, machine learning is a part of artificial intelligence. It sits under the bigger group called AI. To understand the types of machine learning, it is good to know a simple meaning first. Then you can explore more from there.
Simple Definition for Beginners
Here is a simple way to think about machine learning. It is a method to help a computer learn by using examples. You do not have to tell it every step or rule. You give the machine different data points, and it will start to find patterns on its own.
A machine learning model is what you get after the computer finishes learning. This is like a learning model that you can use again. When you train the model, it will be able to look at new information and give you an answer, like a label or a number.
This is one big reason why machine learning is so important in artificial intelligence today. Many AI systems work because their machine learning model gets better as it gets more experience with more data points, not because someone taught it every answer.
Traditional Programming vs. Machine Learning
Traditional programming means you make the rules first. You pick what the computer should do, and it follows those steps. But, when problems get messy in real life, you can need a lot of help from people to keep things working.
Machine learning does this in a different way. Here, you give the computer your input data and the answers you want. A machine learning algorithm finds patterns and learns the rule for you. A simple machine learning example is spam filtering. You feed it many emails and point out which ones are spam. Then, the model starts to see what is “spammy.”
Traditional programming: Rules plus input data make output values
Machine learning: Input data plus output values help you get learned rules (that is, a model)
With traditional programming, you need to rewrite the rules if you want to change things
With machine learning, the model gets better when you train it again with better data sets
Importance of Machine Learning in Today’s World
Machine learning is used in real life because the systems people use today collect too much data for anyone to check by hand. With data analysis, machine learning can find signals in large datasets that many of us would not see.
In business operations, machine learning helps give a company a competitive edge. People use it to do repetitive tasks, guess what will happen next, and make better choices. It works by looking at historical data. It lets companies act based on knowledge, not just a feeling.
Machine learning also makes data science stronger. You can use it for risk, fraud detection, and learning what customers do and want. With machine learning, you do not only ask “what happened?” Instead, you can look at what might happen next.
Role of Machine Learning in Artificial Intelligence
Artificial intelligence is a wide goal. It is about building systems that can act and make choices a bit like people do. Machine learning is a part of artificial intelligence. It is what helps most modern AI work, as it learns from data.
Deep learning is a part of machine learning. Deep learning uses a neural network that has many layers. It became a main reason for growth in computer vision, natural language processing, and generative ai. Generative ai systems now run on big language models.
Computer vision: models can find and know objects in pictures
Natural language: models help with speech recognition and jobs with text
Generative ai: models learn patterns from a lot of training data so they can make new outputs
Easy Analogy to Understand Machine Learning
Think of a learning model like when you practice getting better at a skill. You do not remember a special rule for every situation. You get better by looking at many times something happens and fixing your mistakes. This is close to how machine learning works.
You can see it as a lot like a human brain that uses pattern recognition. When you look at enough examples, you can often guess what the next thing will be. In machine learning, a model works in the same way using data points, but the model learns by changing math steps during training.
Here is a simple way to look at it. Say you want a system to decide if emails are spam. You give it many examples, and it makes some guesses. If it gets one wrong, it will change what it does next time. After a while, these guesses start to get much better. Next, we will turn this into a fast and simple workflow.
How Machine Learning Works – Quick Answer
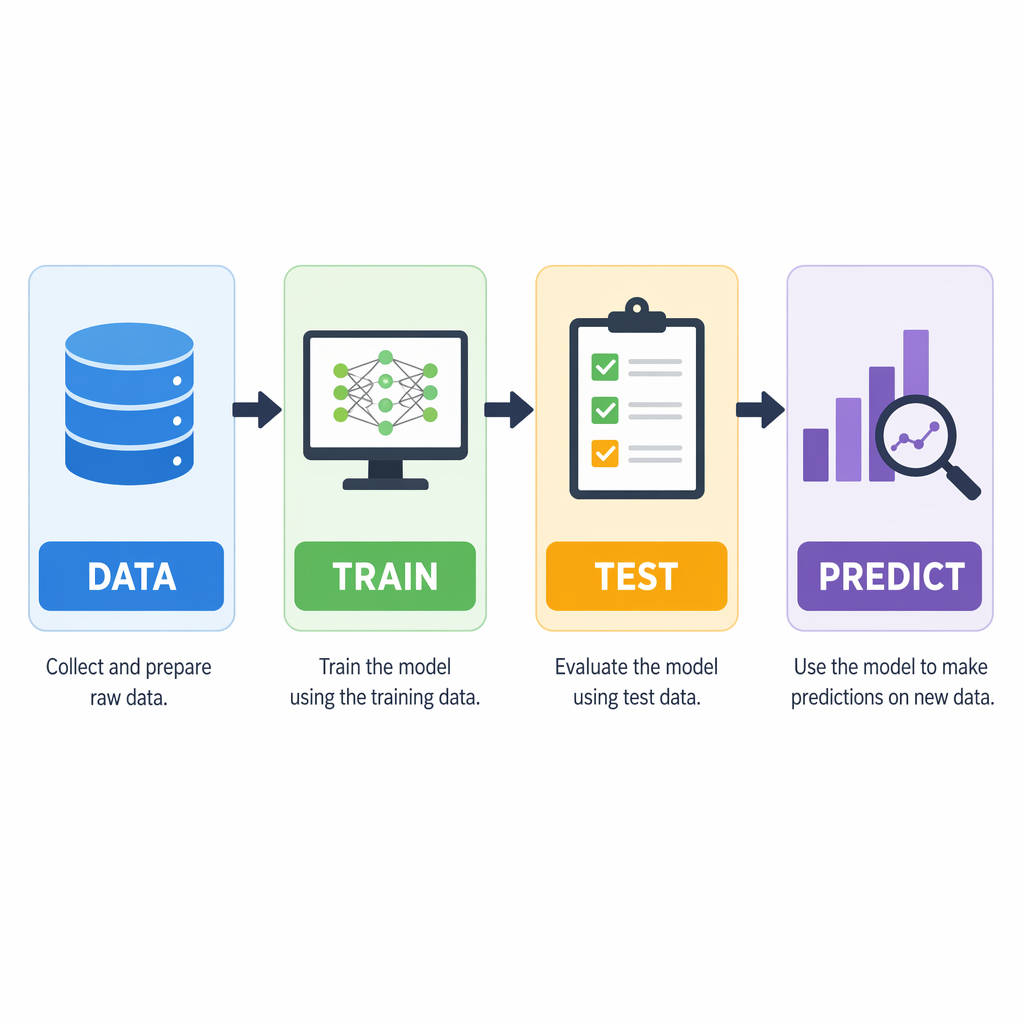 Machine learning works by using past examples to help the machine learn again and again. You start by collecting training data. Then you get it ready for use. After that, you start model training. You check if the model does well with new things you have not shown it before. If the mistakes are high, you can change the data sets or change how you do things. You run the training again.
Machine learning works by using past examples to help the machine learn again and again. You start by collecting training data. Then you get it ready for use. After that, you start model training. You check if the model does well with new things you have not shown it before. If the mistakes are high, you can change the data sets or change how you do things. You run the training again.
The workflow in machine learning is easy to picture. Think of it like a loop. Data goes in, the model learns, then you get some guesses or answers. Feedback from what the model does will help push the next time it learns. The next part will show you each step of this process with simple details.
Step-by-Step Workflow Explained
When you teach a machine learning model, you take it through a step-by-step learning process. Each time you do this, the goal is to help it make fewer mistakes. This way, it gets better as time goes on.
In model training, the machine learning model looks at some training data. It checks where its guesses are right or wrong. Then, it changes the way it works inside. Feature engineering can make things easier by turning raw input data into signals that the learning model can work with.
Collect input data that fits the task
Prepare features by using feature engineering
Run model training and watch how it learns
Test the learning model on other data and check the outcome
Try again with better data or changes if you need to
Collecting and Preparing Data
Everything starts with data collection. The input data can come from many places. You could get it from historical data, product activity, sensors, or social media. It just depends on your use cases.
Raw data is not always ready to use on the first day. You often need to clean the data so you can work with it. This means you have to get rid of mistakes, handle missing values, and fix formats that do not match. This helps make better data sets for training.
Gather data points from trusted sources
Remove duplicates and obvious mistakes
Standardize formats (like dates, categories, or units)
Keep a clear separation between training data and later testing data
Training ML Models
At training time, the machine learning model learns how to match inputs with the right outputs. The learning model uses training data to change how it works. It does this again and again, making small changes to its settings to make fewer mistakes.
Think of it as a model that gets better with feedback. When it gives the wrong answer, the process tells it to change how it looks at each feature. This helps the machine learning model learn over time.
The same algorithm can act in new ways when the data changes. If you give it better data points and clear signals, it usually does a good job. But if the training data is messy or confusing, the model will not learn as much or may have trouble.
Testing and Making Predictions
After training, you test the trained model with separate data. The model has not seen this data before. This is to check if it can work well with new data, not just remember old data.
Then, it is time for prediction. You send new data points into the trained model. It gives you output values. For example, you may get a label like spam or not spam. You can also get a number like a price. The goal is to make good guesses about data it has not seen before.
A simple example is house prices. The trained model looks at past sales. Then it predicts the price of a new house based on new data. If the output values are far from what you expected, you may need to look again at your features, the data quality, or the choice of trained model.
Improving Model Performance and Results
Improving results starts when you do model evaluation. You use performance measurement to see where the model does not do well and to find out why. Data visualization can help you see patterns in mistakes.
Sometimes, problems come from your inputs and not always from your algorithm. Using feature selection helps you take out weak signals that do not help. Dimensionality reduction can make a high number of features simpler. This can help the model learn better. Principal component analysis is one well-known way to do this.
Evaluate results on test data and not just on training data
Make features better with feature selection and by cleaning them up
Use dimensionality reduction when there are too many features
Now that the workflow is clear, let’s talk about what an ml model really is.
Understanding Machine Learning Models
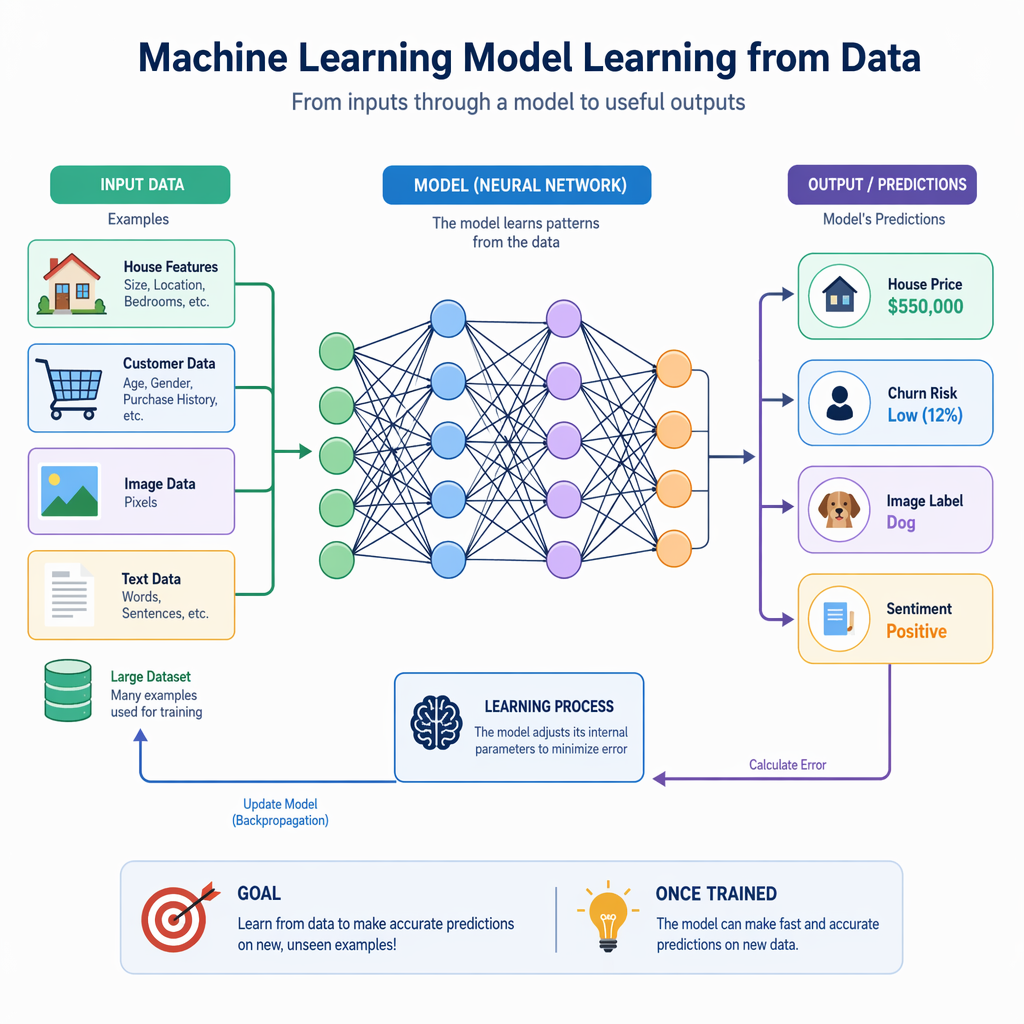 Machine learning models act like trained brains that help you solve tasks. They can spot patterns in training data. This helps them link input variables to output values.
Machine learning models act like trained brains that help you solve tasks. They can spot patterns in training data. This helps them link input variables to output values.
To put it simply, a model is what you use after all of the learning is finished. You give it some inputs, the model looks at them, and then you get results or predictions. Up next, you will find out how machine learning models work and how learning changes into results.
What Are ML Models?
A machine learning model is a computer program. It learns from data, so it can predict, sort, or decide things. The model does not need clear rules for every step. This gives a simple answer to “What is a machine learning model in basic terms?”
The learning process starts during training. At this time, the model looks at examples. It changes what it does, so mistakes are less. After it learns, you can use the model for the real work you want it to do.
You will find machine learning models in many parts of life. They might guess numbers, sort types, or spot things in input data. What the model looks at (the input data) and the main goal can be different each time, but the learning process is there.
How ML Models Learn Patterns from Data
Models get better by spotting patterns. They go through training data. They look for links between things in the data and what happens. If those same patterns keep showing up, the learning model will use them in the future.
The data sets you choose can shape the model. If your data is not complete or is not fair, the learning model could get the wrong idea, even if you use a good way to build it.
That is why feature engineering is so important. If the features fit the problem well, it is easy for the model to learn. If the features are full of extra or wrong things, the model has a hard time and does not do well with new data.
Inputs, Processing, and Outputs Explained
Every ML setup has three main parts: inputs, processing, and outputs. You pick input variables that go in. Then, the system uses what it learned during model training. After this, you get the output values.
Data analysis helps you know what to put in and what to look for. For example, in a spam model, you might use words, sender details, and how a message is built as inputs. The output can tell you if something is “spam” or “not spam.”
Inputs: features you pick from input variables
Processing: the weights and rules made during training
Outputs: what class is guessed or what number is predicted
Difference Between Training and Prediction
Training is the time when the model learns by using training data. The model keeps updating itself many times to make fewer mistakes. This step can take a lot of time. It also needs tuning and good preparation.
Prediction happens when you use the trained model. You put in new data and get a prediction right away. The answer comes from what the model has learned before.
So, here is the key difference: training is about building the ability, while prediction is about using that ability. In real life, teams train, test, and put the model to work. They keep making it better as new patterns show up in the data coming in.
Example: Predicting House Prices with ML Models
A classic beginner example is house price prediction using linear regression. You collect past home sales as input data, pick useful features, and train a model to predict output values (sale price).
The model learns how changes in features relate to price. Then, for a new listing, it estimates a price based on those learned relationships. This is a clear, simple answer to how machine learning works with an easy example.
Feature (Input) | Example Value | Why It Matters in Data Analysis |
|---|---|---|
Square footage | 1900 | Larger homes often cost more |
Bedrooms | 4 | Room count influences demand |
Age of house | 30 | Older homes can reduce price |
Predicted price (Output) | $X | Output values from the model |
Next, let’s walk through the full machine learning process step by step.
The Machine Learning Process Step by Step
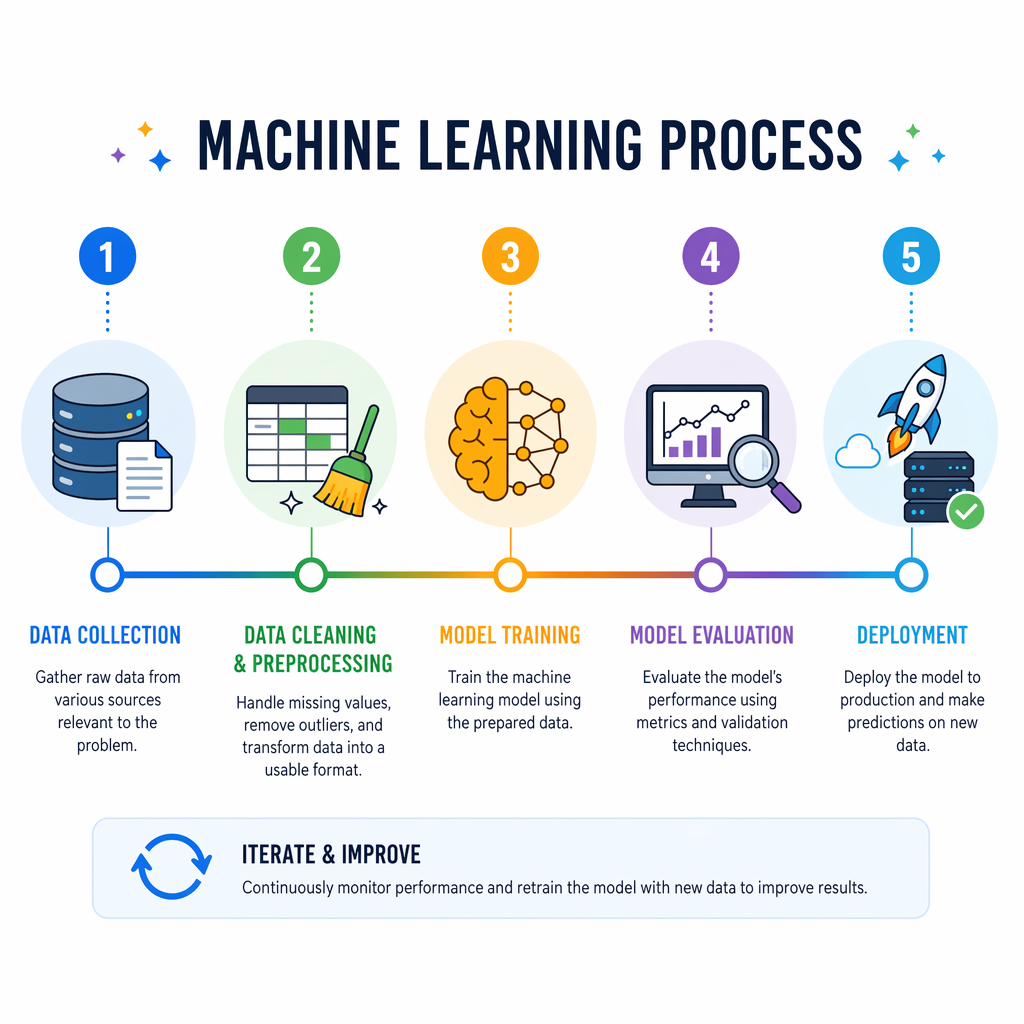 The machine learning process is a step-by-step path you can follow every time. It starts with data collection. Then, you move on to feature selection. After that, there is model training and then model evaluation. Every step is important if you want your results to be steady and good.
The machine learning process is a step-by-step path you can follow every time. It starts with data collection. Then, you move on to feature selection. After that, there is model training and then model evaluation. Every step is important if you want your results to be steady and good.
Once your model works, you will use it in real life when new data comes in all the time. The steps below show how teams build, test, and use models. They help make the machine learning process easy for people who are just starting.
Data Collection Techniques
Data collection is about getting enough examples to learn from. In many use cases, people build large datasets using historical data, like purchases, clicks, transactions, or support logs.
Some projects also use signals from social media, or get information from sensor streams. The most important thing is to make sure the data points show what is really happening. This helps the model work well after it is used.
Use historical data to help with prediction and guessing what will happen later
Get data that shows real user actions, which can help with making things fit each person
Keep the fields the same every time you record data so that later processing is easy
Data Cleaning for Better Results
Raw data can have missing fields, duplicate rows, and odd values. Cleaning up your data takes care of these problems. This makes training more stable and the results more honest.
If you skip this cleanup, the model may learn wrong things. Anomaly detection can help you pick out unusual records that can hurt what you learn from data sets, like in financial or sensor-heavy data.
Fix missing values and categories that do not match
Remove duplicates and clear mistakes
Use anomaly detection to check or flag outliers
Feature Selection in ML Projects
Feature selection is about picking the few inputs that matter most. If you have too many weak ones, they can make learning harder and slow down training. This issue grows when the number of features gets larger.
Dimensionality reduction helps when your data has too many features. You do not need to keep everything. Instead, you squeeze the information into fewer inputs, while keeping what is most important. Principal component analysis is one common way to do this.
The best features are easy to understand, steady, and help your prediction. When you help your model focus on the right features, you often get better results. You do not even need to change the algorithm for that.
Model Training with Practical Examples
Model training is the step where the system learns from what you show it. When you use a supervised learning algorithm, you must provide training data that has known answers. The model uses this to figure out how to match the input to the right output.
For the job of classification, you often start with logistic regression. Many people also use decision trees. The reason is that decision trees make the steps much easier to see than other tough models.
Train a classifier with logistic regression when you need yes or no answers
Choose decision trees if you want to see clear paths for each choice
Train again when new data changes over time
Model Evaluation and Performance Measurement
Model evaluation helps you see if your model is really doing a good job. You do this by looking at how the predictions match the expected results on test data. You also keep track of how well your model does by watching these performance numbers.
Data visualization can help you find problems fast. If you see more errors for one group or type, it is easier to spot when you look at a chart than when you study the raw numbers.
A data scientist often repeats a few steps over and over. They may adjust the training data, change things about the features, do model training again, and then do the model evaluation one more time. By doing this, you do not get models that work well only during training and fail in real-world use.
Deploying an ML Model in Real Applications
Deploying a model means you move it from a notebook to a working system. In business, the trained model takes in new data all the time. It gives answers that help people make choices.
This is how machine learning helps business operations and gives companies a competitive edge. But putting a model out there is not something you can just do once and leave alone. Models should be watched for drift, and you need to update them if their behavior is different.
Put the trained model in an app or a service so you can use it for live predictions
Watch the quality because new data can change the way input looks
Train again on updated data to keep good results
Next, you’ll see the most used type of learning for beginners. This is called supervised learning.
Supervised Learning Explained
 Supervised learning is a way to train a model using labeled data. Here, there is training data where each example shows both an input and the correct answer. The supervised learning algorithm looks at all this and checks if there are any mistakes. It then works to get better.
Supervised learning is a way to train a model using labeled data. Here, there is training data where each example shows both an input and the correct answer. The supervised learning algorithm looks at all this and checks if there are any mistakes. It then works to get better.
If you have wondered, “How does supervised learning work, and can you give a simple example?” you can think about spam filtering or house pricing. You give the model data where the outcome is already known. It learns from this, and later can guess what the answer will be for new inputs. Next, let’s break it down in an easy way.
What Is Supervised Learning?
Supervised learning is a way where you teach a model using examples that already show the right answer. These answers are called labels, and the model learns by seeing what a correct result is.
In model training, the system makes guesses, checks them with the labeled data, and then changes itself to make fewer errors. After some time, it finds patterns that link the input with the output.
One clear way to see this is in email spam detection. You give the model emails and label them as spam or not spam. When the model is done learning with that training data, it can look at new emails and guess if they are spam based on what it saw before.
Role of Labeled Data in Supervised Learning
Labeled data is important because it works like an answer key. If you do not have it, the supervised learning algorithm will not know if its guess is right. Labeled data gives the learning a clear goal that you can measure.
Most of the time, each record has input variables and the matching output values. The model looks at how changes in input variables can change the output values. Training gets better over time as the gap between the guess and the label gets smaller.
Inputs: the input variables (like words in an email)
Labels: the output values (spam or not spam)
Feedback: the model makes changes using the errors it finds
Popular Examples: Email Spam Detection & Student Performance Prediction
Two simple supervised learning use cases are email spam detection and student performance prediction. In both of these, you work with training data that has labeled outcomes. This helps the model learn by looking at past examples.
For email spam detection, the model uses labels like spam or not spam. For student performance prediction, labels could be test scores or if the student passed or not. The model gets better by finding patterns that link the inputs and the results.
Spam use case: classify emails as spam or not with labeled data
Student use case: use training data from the past to guess results
Both use cases make use of supervised learning and keep getting better over time
These examples show how working with labeled data and training data makes it easier to improve the results.
Advantages and Limitations of Supervised Learning
Supervised learning is good when you have enough labeled data. You also need a clear target in mind. It is easy to check if it works by comparing what the model does to the real answers during model training.
But there are some problems too. Getting labeled data costs time and money. Models can also take on bias from the data if the labels have unfair ideas in them.
Advantages: clear feedback loop, strong performance on defined targets
Limitations: labeling effort, risk of bias, performance can drop when data shifts
So, to put it simply, you need enough good labeled data, and you need to check for problems while doing model training.
Conclusion
To sum up, knowing how machine learning works helps you learn about ideas that are very important in today's tech world. When you learn about things like supervised learning and unsupervised learning, you see how algorithms look at data, spot patterns, and make smart guesses. No matter if you are new to machine learning or want to know more, learning about it gives you many chances to use it in different areas. As you keep looking into this field, think about getting a free consultation to find out how machine learning can help you, whether at work or in your personal life. Be ready for the future of AI and give yourself the tools you need to get around in this exciting space.